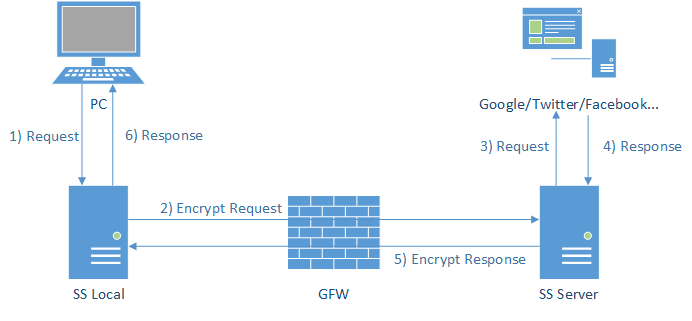
就像老牛吃南瓜——无从下口,我们应该从哪里开始?代理软件的核心是转发流量,用 v2ray 中的名词,不管是 local 端还是 server 端,都需要 inbound(入站)和 outbound(出站)。由于 local 端和 server 端运行的是同一套软件,我们只需暂时将注意力集中在 local 上的设计即可。
// ---------- for RequestVote ---------- type RequestVoteArgs struct { // Your data here (2A, 2B). Term int// candidate's curTerm CandidateId int// candidate requesting vote }
type RequestVoteReply struct { // Your data here (2A). Term int// currentTerm, for candidate to update itself VoteGranted bool// true means candidate received vote }
func(rf *Raft) sendRequestVote(server int, args *RequestVoteArgs, reply *RequestVoteReply) bool { ok := rf.peers[server].Call("Raft.RequestVote", args, reply) return ok }
// ---------- for AppendEntries ---------- type AppendEntriesArgs struct { Term int// leader's curTerm LeaderId int// so follower can redirect clients }
type AppendEntriesReply struct { Term int// currentTerm, for leader to update itself Success bool// true if follower contained entry matching prevLogIndex and prevLogTerm }
在 type Raft struct 中增加了一些 paper 中提到的本实现需要用到的字段,包括上面提到的接受 RPC 参数的 channel:
1 2 3 4 5 6 7 8 9 10
// Your data here (2A, 2B, 2C). // Look at the paper's Figure 2 for a description of what // state a Raft server must maintain. curTerm int// current curTerm state RState // current state votedFor int// candidate id that received vote in current curTerm
voteChan chan voteParam // channel for vote request entryChan chan appendEntryParam // channel for entry request
有关 RState interface 和具体的实现,定义如下:
1 2 3 4 5 6 7
type RState interface { Run(tf *Raft) }
type Follower struct{} type Candidate struct{} type Leader struct{}
timer := time.NewTimer(electionTimeout()) for { select { case <-timer.C: // d 超时 case reply := <-replyChan: // g RequestVote 回答 case vote := <-rf.voteChan: // e RequestVote 请求 case entry := <-rf.entryChan: // f AppendEntries 请求 } } }
首先自增 curTerm,发送 RequestVote 请求其他节点的选票,随后开启循环等待事件驱动,其中 d,e,f 遵随 paper 所描述即可,只需要注意加锁释放锁的时机,这里简单贴一下代码:
rf.mu.Lock() if reply.Term > rf.curTerm { // received larger term, become follower rf.curTerm = reply.Term rf.votedFor = -1 rf.state = &Follower{} rf.mu.Unlock() return } elseif reply.Term == rf.curTerm && reply.VoteGranted { // received a grantVote grantedCnt++ if grantedCnt >= minVote { rf.state = &Leader{} rf.mu.Unlock() return } } rf.mu.Unlock()
leader.go
框架:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
func(l *Leader) Run(rf *Raft) { // TODO: send heartbeat // TODO: send AppendEntries RPCs to all other servers
// make heartbeat timer timer := time.NewTimer(heartbeatTimeout()) for { select { case <-timer.C: // h 超时 case reply := <-replyChan: // k AppendEntries 回答 case vote := <-rf.voteChan: // i RequestVote 请求 case entry := <-rf.entryChan: // j AppendEntries 请求 } } }
funcWorker(mapf func(string, string) []KeyValue, reducef func(string, []string)string) { for { needWordReply := NeedWorkReply{} ok := call("Coordinator.NeedWork", &NeedWorkArgs{}, &needWordReply) if !ok { // 当 RPC 调用失败,我们认为 Coordinator 任务完成退出, // 所以 Worker 理应退出终止 // Coordinator finish its work break } if needWordReply.T.Type == Map { // 处理 Map 任务的逻辑 filename := needWordReply.T.Filename file, err := os.Open(filename) if err != nil { log.Fatalf("cannot open %v", filename) } content, err := io.ReadAll(file) if err != nil { log.Fatalf("cannot read %v", filename) } file.Close() // 得到单个文件的 Key-Value kva := mapf(filename, string(content))
// 生成 intermediate 文件的逻辑 // 首先计算每个 Key 的 reduceId,保存在 intermediate 这个二维切片中 intermediate := make([][]KeyValue, needWordReply.ReduceCnt) for _, kv := range kva { reduceTask := ihash(kv.Key) % needWordReply.ReduceCnt intermediate[reduceTask] = append(intermediate[reduceTask], kv) } // intermediate[i] 对应 mr-{taskId}-{i} 这个中间文件 // 以 paper 中提示的使用 json 的方式写入 for i := 0; i < needWordReply.ReduceCnt; i++ { ofilename := fmt.Sprintf("mr-%d-%d", needWordReply.T.TaskId, i) // ofile, _ := os.Create(ofilename) tf, _ := os.CreateTemp("./", ofilename) enc := json.NewEncoder(tf) for _, kv := range intermediate[i] { enc.Encode(&kv) } tf.Close() os.Rename(tf.Name(), ofilename) } } elseif needWordReply.T.Type == Reduce { // 处理 Reduce 任务的逻辑 // 找出目录下所有对应该 Reduce 的文件名 // find all files corresponding to this reduce task var filenames []string files, err := os.ReadDir(".") if err != nil { log.Fatalf("cannot read current directory") } for _, file := range files { if file.IsDir() { continue } filename := file.Name() prefix := "mr-" suffix := fmt.Sprintf("-%d", needWordReply.T.ReduceId) if strings.HasPrefix(filename, prefix) && strings.HasSuffix(filename, suffix) { filenames = append(filenames, filename) } }
// 对所有已找到的文件进行读取 // do reduce job var kva []KeyValue for _, filename := range filenames { file, err := os.Open(filename) if err != nil { log.Fatalf("cannot open %v", filename) } dec := json.NewDecoder(file) for { var kv KeyValue if err := dec.Decode(&kv); err != nil { break } kva = append(kva, kv) } }
// 对该任务进行 Reduce 调用,逻辑和 mrsequential.go 完全一致,代码直接 copy // copy from mrsequential.go sort.Sort(ByKey(kva)) oname := fmt.Sprintf("mr-out-%d", needWordReply.T.ReduceId) ofile, _ := os.Create(oname) i := 0 for i < len(kva) { j := i + 1 for j < len(kva) && kva[j].Key == kva[i].Key { j++ } values := []string{} for k := i; k < j; k++ { values = append(values, kva[k].Value) } output := reducef(kva[i].Key, values) fmt.Fprintf(ofile, "%v %v\n", kva[i].Key, output) i = j } ofile.Close() } else { // unknown task type log.Fatalf("unknown task type: %v", needWordReply.T.Type) }
考虑到需要记录由 dup(fd) 创建的文件描述符用于删除,加之 C 需要手动实现类似动态数组之类的数据结构,我们偷懒使用递归替代手动存储的工作。我们将这个操作使用 int recursiveDup(int fd, int fd2) 完成,我们定义返回值为成功复制后的 fd2 ,若失败,则返回 -1 :